Background
Before going into the main dish, let’s clarify the regression requirement.
Our team is aim to do business functional testing and use grey-box to design test cases. Thus if the requirement satisfies the following principles, it will be considered into a regression requirement:
- Pure technical improvement like code refactoring, adding monitoring, etc.
- Low impact on business logic that won’t bring any feeling of end-user and won’t impact our key metrics
Firstly (#1), we notice lots of regression requirements coming that occupy QA’s time to execute repeatedly every week. Generally, it should put major attention on new features or some changes with big impact, however, it doesn’t mean regression requirement is not important.
Secondly (#2), at that time, we already have a certain amount of automation testing(AT) cases running every night and have a clear responsibility for AT nightly issue triaging and maintenance. In the team, most QAs are fully occupied with new feature testing and use manual testing, which is difficult to push AT case coverage contribution.
Thirdly (#3), there is a gap to cooperate with developers’ code delivery and testing tasks arrangement. We will have low priority tickets pending on the QA side over several weeks or before the release date, ask QA to quickly sign off the Jira tickets in a short time, which will bring a big quality risk.
The last but not least (#4), we are thriving to build testware (AT) to test software, so we have to find a good way to measure our AT’s ROI and we decided to choose AT sign-off ticket number as our AT’s key ROI metric. That means we have to find a way to involve more stakeholders to our AT process, so they can raise sign-off requirement more and amplify our AT’s outcome.
Given with above requirements, the challenge to us has become:
- How could we customise an way to sign off regression testing using AT (to satisify the requirement of #1, #2, and #3) efficiently and integrate AT into SDLC deeper to embrace more stakeholders (Devs and PMs) to be involved in the process (to satisfy the requirement of #4)
Solutions
The ultimate solution is the automation CI/CD pipeline. However, it needs lots of pre-conditions like a good AT coverage rate, good QA’s stability, and clear SDLC management processing, etc. In the early stage, it is a wise choice to provide a simple and workable solution and then keep continuous improvement of the solution.
In this phrase 1:
- Re-use existing AT cases to fully/partially support upcoming tickets
- Encourage to develop AT cases during case execution, especially P0 cases
- Standardise formats and processing of these pending QA Jira tickets
- We heavily leverage Jira’s labeling in our AT sign off process
Diagram
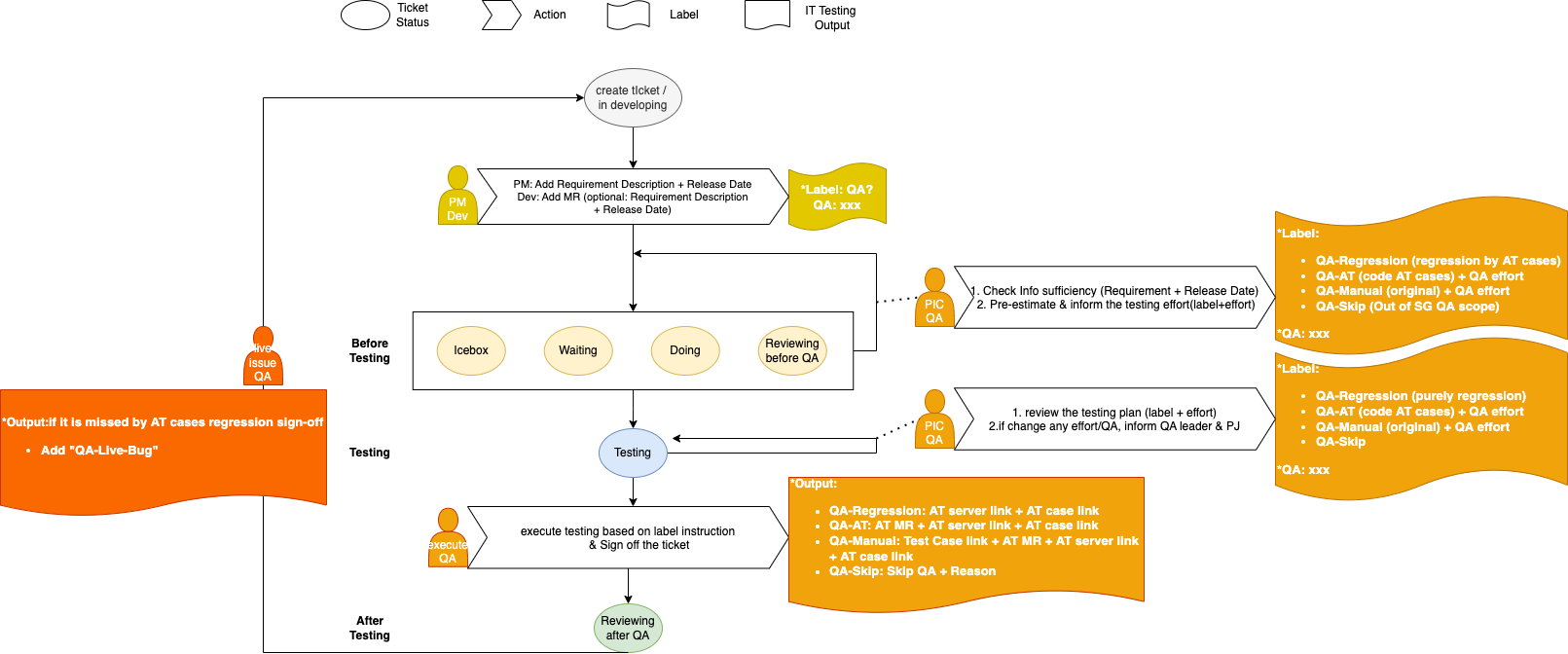
Use Case
- A developer wants to add logs to the code. He needs to create a Jira ticket with an object explanation, even add some implementation design and concerns.
- In the Jira ticket, if he notices this one need to go through QA, he will mark ‘QA?’ label an ideal release date
- QAs will base on in charge scope to review all new tickets with “QA?” and rely on the info to determine the testing strategies like skipping(QA-Skip), regression testing(QA-Regression), etc.
- After testing requirement classification, we could pick up “heavy” tickets first and inform project managers to arrange more resources in advance and make “light” tickets under control.
- Until one day before the release date, we will find a fixed time to solve all “light” tickets. Like a regression ticket, we will deploy our server with a dedicated branch and run all AT cases of this server on Jenkins. If all cases passed, we will sign off this ticket with the Jenkins report.
Next Stage
More automatic CI/CD pipeline
Will involve GitLab inside to detect the exact code changes, test case chosen, failure report, etc.
Outcome
In the whole year of 2021, we have around 1000 tickets going through QA team. Over 50% of tickets are fully/partially using AT cases regression to sign off tickets.
Such an impressive number!
For the big code refactoring, we could cut down ~60% of efforts, and the rest effort is mainly used for config settings and coverage improvement.
About the author: Sichun Zheng
