Background
One of the most essential key metrics we use to evaluate the ROI of test automation is test stability. Currently all of the test reports/tools/plugins in the test community calculate the test pass rate based on the latest test result. However test stability should be an overall test pass rate which needs to be calculated based on test execution data in a given sliding window.
Say we have around 40K automated test cases and we have around 100K test executions every day (which means for each test case it gets executed up to three times within 24hours). To evaluate test stability, we cannot just simply calculate the test pass rate based on the latest test output because if we consider the below scenarios:
- At 2AM, the nightly run executes 40K cases with 4K failed cases
- At 9AM. We conduct nightly triaging for the failed cases execute another round of 40K cases with 2K failed cases
- During working hours, we use AT to help sign off feature testing tickets and execute yet another 40K cases with 0.5K failed cases
The current test report tools will just provide the pass rate for 3) with a pass rate of (40K-0.5K) / 40K*100% = 98.75%. This pass rate is just a real-time pass rate for that batch of execution which does not reflect our test stability correctly. If we use 24hours as a time window, the overall pass rate should be ((40K-4K) + (40K-2K) + (40K-0.5K) / (40K+40K+40K+) * 100% = 94.5%only.
Based on the above analysis, we can also conclude that the test pass rate from a single test report really does not tell you much about the test stability. On the contrary, if you look at a whole set of test reports in a given time window, then you can fully understand the test stability. This conclusion challenges us to find a way to accumulate our each and every test report in a sliding window and then conduct calculations based on it.
To tackle this challenge, let us now try to find a way to accumulate test reports in the past 24hours. Given that every day we have 100K test executions, we observe that our test results are actually just like streaming data. If we consider each of the test case results as an event, that essentially means we are building a event-driven solution which is capable of collecting streaming data in a sliding window (24hours) to be processed and eventually show the real-time stats (real time test stability in 24hours).
Solution Design
~~INFLUXDB~~
Before we go further, let us take a step back and understand what is influxDB and why we use it. One of the main reasons is that it is a time-series database, a.k.a data with timestamps which allows for analyzing and monitoring time-sensitive data. On top of that, InfluxDB is also able to handle high I/O load which allows for efficient retrieval and even real-time feedback. So influx DB is perfectly matched with our needs to stash our streaming event data (test results).
Here are some other terms which would help in understanding how it pieces together as we discuss further how it is set up.
- Measurement: The group of data that uses a similar data storage structure. Think of it as a subset of your database.
- Fields: A required component consisting of a key:value pair that stores the data you want.
- Tags: Similar to fields, it is also a key:value pair that stores data. The main difference is that tags are indexed data. Which also translates to it being processed much faster as compared to fields when querying. As such, it is important to consider which fields to be used as tags.
~~GRAFANA~~
So we choose influx DB to stash our real-time test results, now we need to visualize data with a dashboard for better observability. Grafana is an out-of-box dashboard solution which empowers you to query, visualize, alert on and understand your metrics no matter where they are stored. Create, explore, and share beautiful dashboards with your team and foster a data driven culture
~~KICK-OFF~~
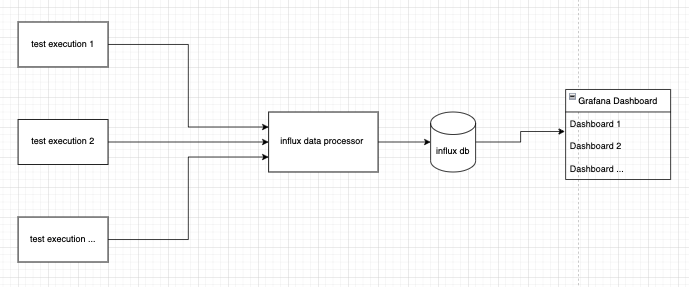
Now let us see how we can easily do so using a base architecture setup that includes Grafana and InfluxDB. Test results from all our tests are consolidated in a DB which acts as a source of data for Grafana to draw upon for display.
~~INITIAL-SETUP~~
To begin, there would be a need to install both Grafana and InfluxDB with instructions that can be easily followed and found here for Grafana and here for InfluxDB. InfluxDB will act as a data storage which Grafana will tap into to further process and display as according to how you would like it to be.
After the installation, we would need to allow your Grafana to access the data in your InfluxDB via HTTP. Simply input the configurations of your influxDB under
Grafana → Configuration → Data Sources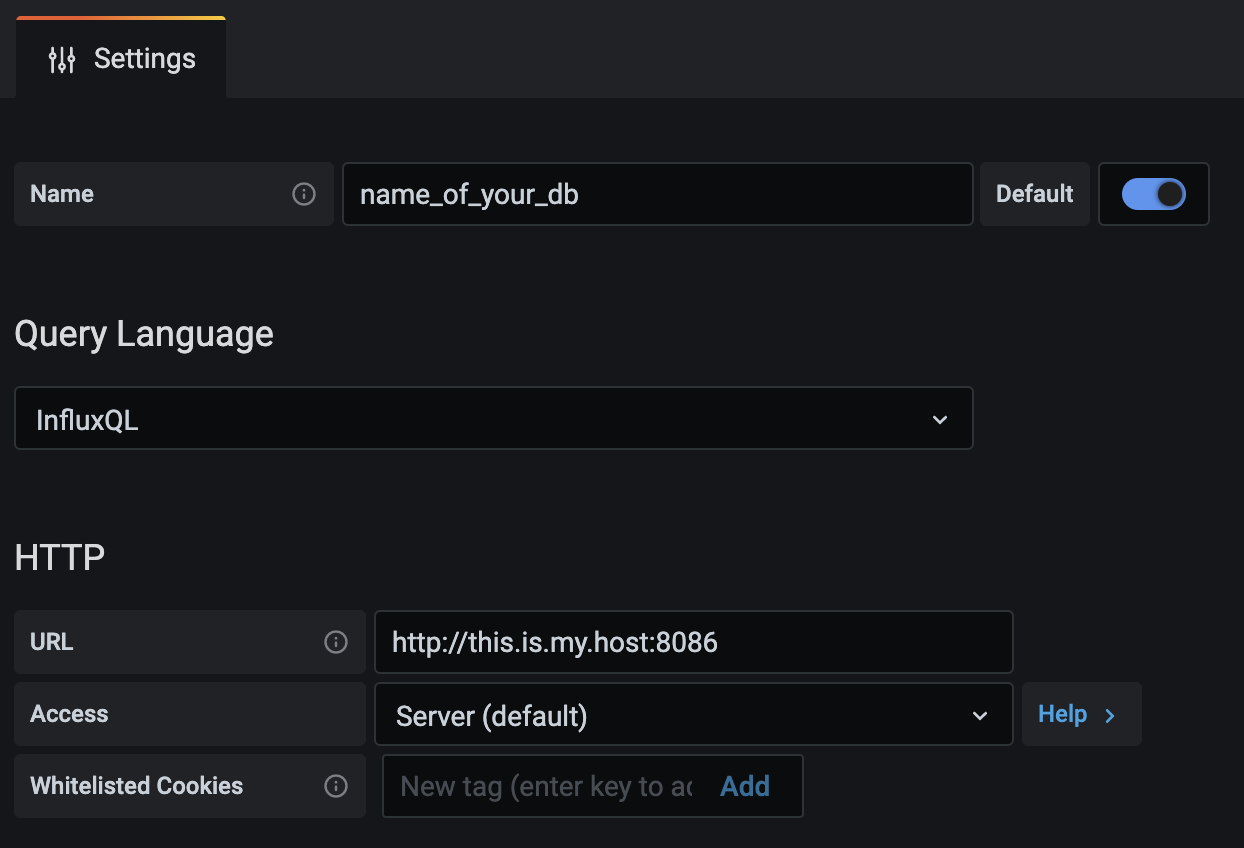
With that, your base setup is complete!
~~Gathering Test Results~~
Next let us store some data in our InfluxDB. Here we demonstrate a simple InfluxDB Client in Golang that can be easily inserted anywhere in your code or processes to gather results of your automated test.
import influxdb2 "github.com/influxdata/influxdb-client-go/v2"
func GetInfluxClient() influxdb2.Client {
return influxdb2.NewClient(InfluxUrl, InfluxToken)
}We then write the function which uses this client to push one datapoint into our InfluxDB.
func WriteToInflux(measurement string, tags map[string]string, fields map[string]interface{}) error {
ctx := context.Background()
//Init Base Client
client := GetDefaultInfluxClient()
defer client.Close()
//Init write client from base
writeClient := client.WriteAPIBlocking(InfluxOrg, InfluxBucket)
//Creating a new point based on input parameters
p := influxdb2.NewPoint(measurement, tags, fields, time.Now())
//Writing to InfluxDB
err := writeClient.WritePoint(ctx, p)
if err != nil {
log.Println("Error when writing to Influx: ", err, "for measurement: ", measurement)
return err
}
return nil
}And that is it, as straightforward as that! Now all we have to do is just place this function wherever we want to collect data for example in an automated test like this:
func Test_getApiExample(t *testing.T) {
//Initialisation
service, client, err := serverA.New()
assert.NoError(t, err)
//Example API Call
req := service.BuildDefaultReq()
resp, err := client.SendApi(req)
assert.NoError(t, err) expectedResp := service.GetDefaultResp()
assert.EqualValues(t, expectedResp, resp)
//Store API Response in InfluxDB
err := WriteToInflux(
"all_test_results",
map[string]string{"run_id": req.GetTimeId()},
map[string]interface{} {
"case": "Test_getApiExample"
"error_msg": resp.GetErrorMsg(),
"error_code": resp.GetErrorCode(),
"exec_time": resp.GetExecTime(),
"status": resp.GetStatus,
})In short, we simply call the WriteToInflux function whenever we want to input a datapoint with the corresponding measurement (“all_test_results”), tags (“run_id”) and fields (“error_msg”, “error_code”, “exec_time”, “status” and “case”).
~~DISPLAYING ON GRAFANA~~
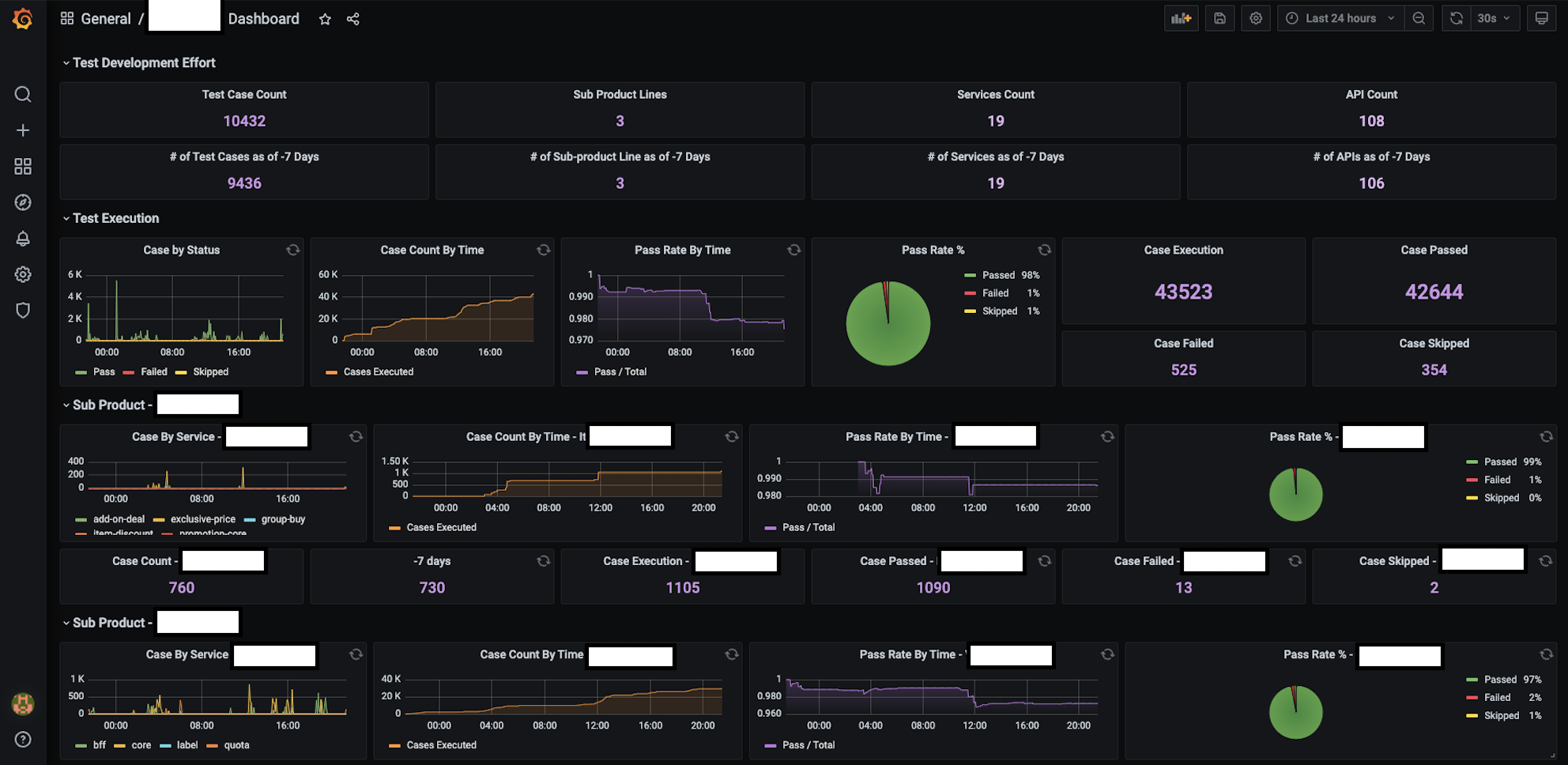
Now to the main purpose of all the preparations before this, we will first create a new Dashboard on Grafana which can be found on the side-nav bar in your grafana page.

We then create a new panel which is found in the top-nav bar of your newly created dashboard.

We then choose how we want to display. Grafana itself offers many ways to display the data such as Stat, Time-series, Graph, Gauge, Bar-gauge, Table, Text, Pie-chart, List, Logs and more.
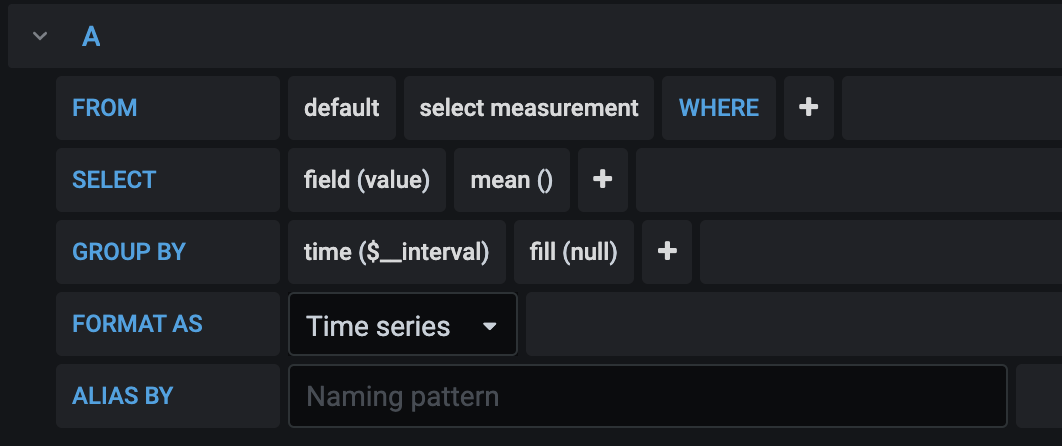
Then we pair the above configuration with the data we want to display from the query section of in the panel which can either be in Flux query, which is very similar to the commonly known SQL language, or a click-drag-drop UI as provided.

With the basics down, let us explore how we can showcase our test results and some possible uses of such display metrics.
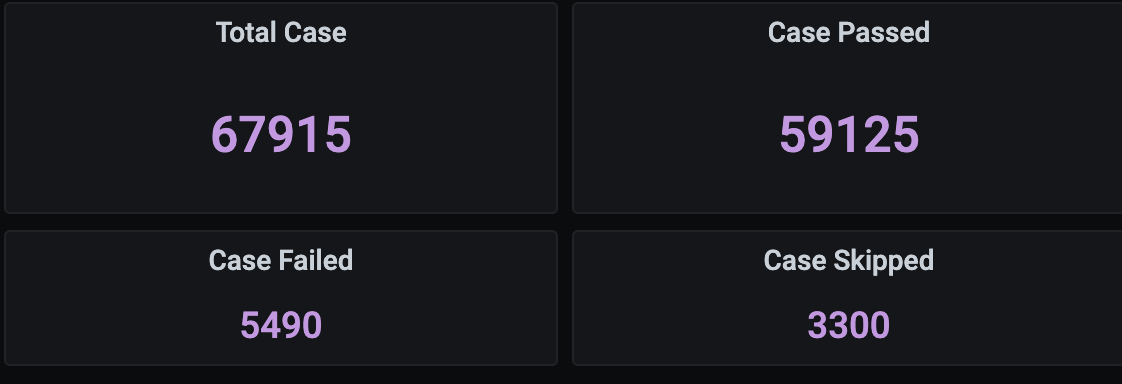
We can easily obtain the total number of ATs which have ran in total within a certain time frame, letting us know either the number of cases its status.

Another way to present such stat data might be through a pie-chart as above which gives a pictorical overview of the % of your test status. To expand upon this information further, we can also generate a time-series representation to see when the ATs are used.
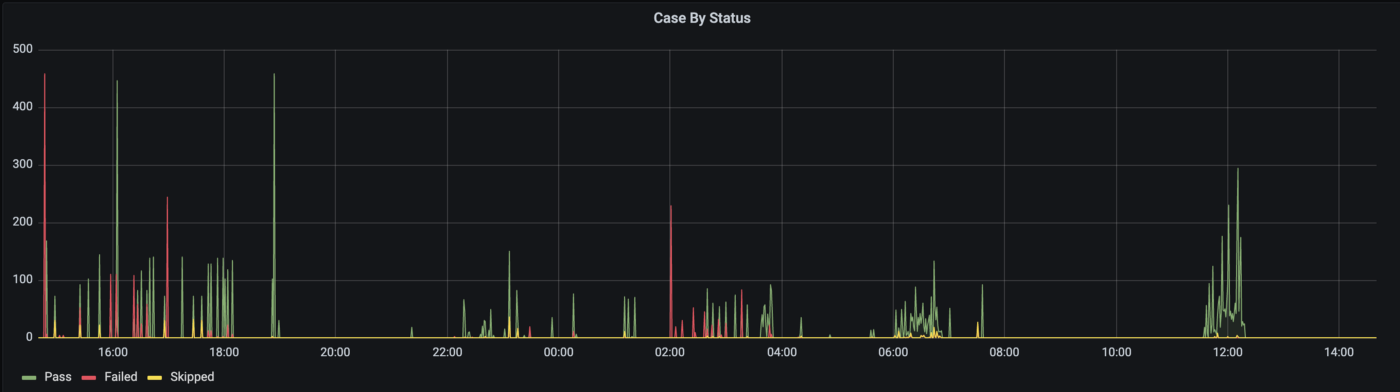
As can be interpreted , nightly regressions are running from about 10pm to 8am. The ATs are also heavily used around 3 to 6pm, as well as 12pm which goes to show that QAs are actively using the ATs to assist in their testing, be it for full or partial regression, and even initial checks of new product code additions or edits.
On the other hand, we can use the above graph to see the availability of the test infrastructure which can suggest where new ATs should be added. For example, somewhere between 12.30am to 1am or around 4.30am to 5.30am is a good empty slot which would decrease the chances of conflicting tests.
Having seen all the different graphical representations, you might be surprised to find that the Flux query passed to obtain the data for each of them is the same for all the displays shown above!
1. Total Cases:
COUNT(“cases”) FROM “all_test_results” AND $timeFilter GROUP BY time($__interval) fill(null)2. Cases Passed:
COUNT(“status”) FROM “all_test_results” WHERE (“status”='success') AND $timeFilter GROUP BY time($__interval) fill(null)3. Cases Failed:
COUNT(“status”) FROM “all_test_results” WHERE (“status”='failed') AND $timeFilter GROUP BY time($__interval) fill(null)4. Cases Skipped:
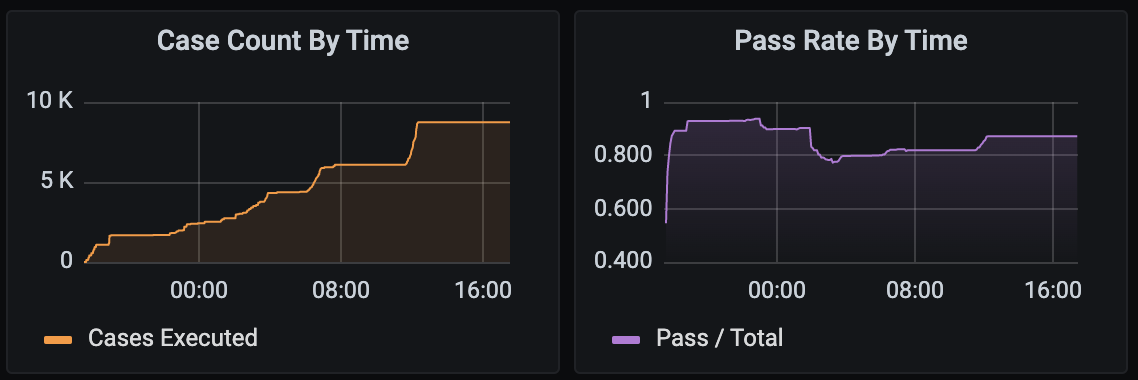
COUNT(“status”) FROM “all_test_results” WHERE (“status”='skipped') AND $timeFilter GROUP BY time($__interval) fill(null)We can observe that with a few simple queries, we can generate a myriad of different ways to present our data quickly and easily. We can also look at this from another point of view such as case count or pass rate across time. Such graphs can derived from our current data gives us a clearer overview of the stability and quantity of ATs ran during certain points of time.
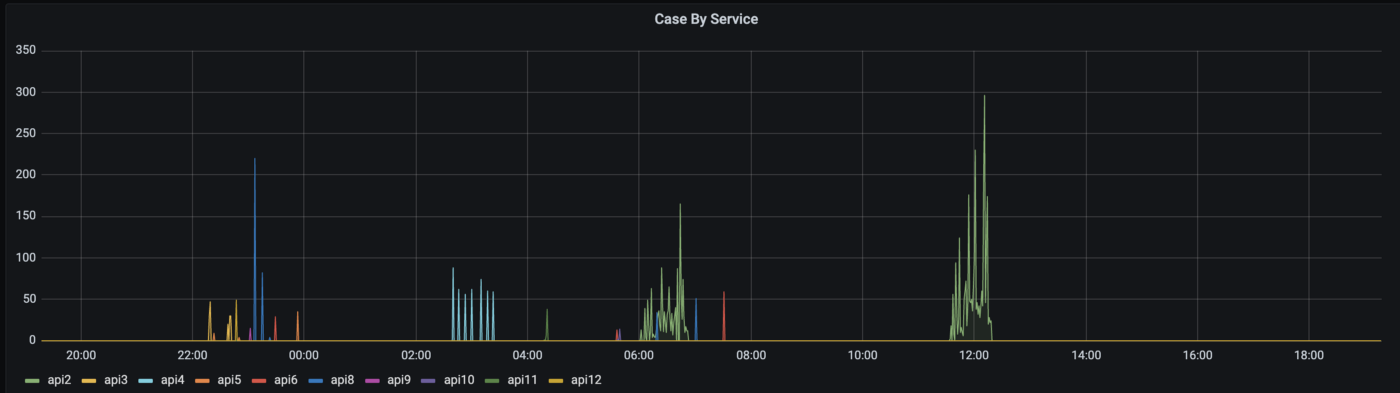
Furthermore, with some small tweaks and adjustments, we can even break down the data into smaller components such as each individual API, server or even aggregate the data across different services or teams to get a larger overview, letting us better and quickly understand at a glance our test infrastructure, condition and status.
Grafana also supports the detailed configurations such as the components of a graph (axes, bars, lines, area, legend, line width etc.) with options to override some default display settings if necessary and transformation of your data including changing of display data via joining, calculations, ordering, hiding or renaming.
~~MOVING FORTH~~
With the basics down and the metrics up, we then turn to look at the more minute configurations and some important things to note when doing your basic setup which are of course not exhaustive.
1. Retention Policy: How long data is kept in the DB including replicates (if any) and shard duration. By default, it is kept infinitely but that would be a waste of resources, space and processing powers. One might consider how relevant such test results or any sort of data will be as time passes. More information about this can be found here.
2. Managing Database: As with all databases, knowing how to manage it is as important as knowing how to use it. To check on the data not only through Grafana but also through influx-cli can help provide more clarity and consideration when building your own dashboard pipeline. More information about this can be found here.
3. Continuous Query: InfluxDB supports continuous query which sends queries automatically and periodically. While the usage of this is for the more advanced, it offers amazing versatility to the usage of data especially when some are dependent or nested in another. More information about this can be found here.
4. Grafana Plugins: Grafana is also supported by plugins which not only offers itself as a more powerful display tool, but also integrations with other services such as Jira, Gantt and even other types of DBs. All their available plugins can be found here.
5. Integrations: With the basic architecture, we can add on other services along its flow or add it to another, easily integrating it into any part of our pipeline to track test data and metrics. One such example would be to use the influx client as an external tool which collects and constantly updates DB as each Jenkins Job is ran.
With that, we have gone through how we can setup a simple Grafana dashboard using InfluxDB and its flexibility for displaying test data in several ways depending on the story you want to tell. Once we are able to use the data obtained during testing and usage of our ATs , will we then be able to know where to focus on and improve our testing components.
As obvious as it is, let us also emphasise the importance of ensuring that your data and metrics are relevant, accurate and useful for it would truly be done “for nothing” should it be otherwise.
Lastly, we hope this article will not only be useful for introducing how to measure and display test data, but also for any types of data which might be of interest to be measured. The way you want to measure, track and present your data is limited only by your imagination.
Big thanks to Huang Luohua for his guidance throughout and Elaine Chong for her initiative in kicking off this project as well as assistance provided throughout!
All of the codes can be cloned here: https://github.com/luohuahuang/junit-influx-client
Go wild.
About the author: Joseph Chu
